下一代 Bangumi Research 架构设计
Bangumi Research,即众所周知的 https://ranking.ikely.me,是一个展示 Bangumi 动画科学排名的网站。然而仅仅展示科学排名并不能充分填充这个 title 的 scope。事实上,我们希望它能做更多的事情,但是既有的网站架构限制了它唯一能做的事情就是展示科学排名。如果你查看过它的代码,你会发现它所做的事情仅限于从一个 Azure FileShare 里面定时读取最新的排名,如果发现排名更新了它就下载它并替换已有的排名。如果我想要做更多复杂的东西,比如说点开每个番组并查看它的 details,我是不是还得让它再读取一个文件?所以你可以看到这个网站的运作逻辑是非常简单的。
那么我希望 Bangumi Research 是一个什么样的网站?在我的理想中,它应该:
- 展示科学排名
- 展示每个番组的详细资料并包括一些有趣的数据(which requires extra data mining
- 使用 tag 系统把每个番组连接起来
- ……
但是目前为止,我还没有把 Bangumi Research 设计成一个可以登陆的客户端的打算。
经过若干周末的努力,下一代 Bangumi Research https://chii.ai 渐成雏形。chii.ai 来源于 Bangumi 的域名 chii.in。以下是这个新的网站的工程设计:
后端设计
用户访问 Bangumi Research 并不会发生写操作,而且用户最主要的目的就是访问我们的科学排名。除此之外,用户还可能会查看番组的详细信息,以及进行 tag 搜索。我不需要关心查看番组信息的 API,因为可以直接复用 Bangumi API。我主要关注以下三个 API 的设计(这只是概念上的展示,实际实现有所不同):
/api/rank
这个API 应该返回一个数组,其数据结构为
1
2
3
4
5
6
7
8
9
10
11
12[{
int id;
DateTime date;
string name;
string nameCN;
int rank; // Bangumi原排名
int sciRank; // 科学排名
string type;
int votenum; // 评分人数
int favnum; // 收藏人数
List<Tag> tags;
}]这个就包含了番组一些基本信息以及连带的 tags。这么设计 API 纯粹就是 Bangumi API 没有返回番组 tags,所以我需要自己设计系统返回 tags。
Tag的数据结构为:1
2
3
4
5
6{
string Tag;
int TagCount;
int UserCount;
double Confidence;
}其中
TagCount是该番组被标注为该标签的次数,UserCount是所有参与用标签标注该番组的人数。Confidence是一个事先用某种机器学习算法算出来的值,它表示该标签隶属于该番组的确信度。用户实际在查看番组下的标签的时候,这个字段会用于隐藏某些标签。/api/tags
这个 API 返回所有已有的 tags。其数据结构为:
1
2
3
4[{
string Tag;
int Coverage; // 该标签被标注到的番组个数
}]
/api/relatedtags
这个 API 返回所有与被搜索标签有关的 tags。其数据结构同上。
/api/searchbytags
这个 API 返回所有与标签相关联的条目。其数据结构不再赘述。
那么我们需要数据库支持这样的操作。理论上两张表:Subject 表和 Tag 表。Subject 表存储所有番组条目信息,以番组 id 为主键。Tag 表存储标签信息。咋一看标签与条目属于多对多的关系,但是在上面的 API 设计中每个标签在不同的番组中有不同的 Confidence,这就使得我们要把标签与条目设计成多对一的关系:在 Tag 表中,每个标签由其标签内容和关联条目唯一确定。另外,Subject 表应该存放科学排名。但是在 Bangumi Spider 中科学排名被生成为一个单独的文件,为了兼容这种历史遗留问题我们就把科学排名也作为一张表,以一对一的关系与 Subject 表以外键连接。
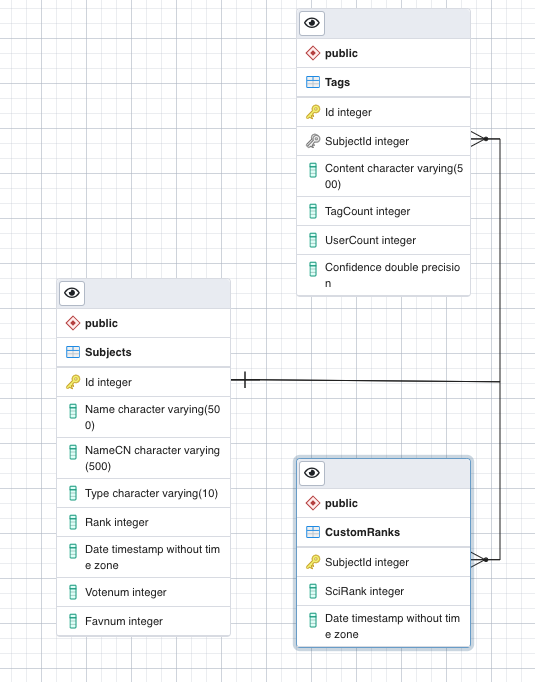
chii.ai 继续沿用 ASP .Net Core 开发后端。有 Linq 和 EntityFramework 的技术支持使得开发体验良好。该 web server 提供若干 restful API 接口。
为了接入 Bangumi API,我另外使用了一个 node 服务把数据库 API 与 Bangumi API 整合成一个 unified API 接口。当然,我也可以用一个 nginx 服务器代理 Bangumi API 的服务,但是我真正的意图是想在前端使用 GraphQL。所以,这个 node 服务是一个 Apollo GraphQL Server,提供整合的 schema 和 API 接口。
前端设计
为什么要用 GraphQL?如果仅仅是“用 GraphQL 那套接口开发”这无疑就会降低我选择这个技术的可能性,毕竟它可能还没有 Restful API 方便。但是 Apollo GraphQL 的生态系统是如此之成熟,这使得选用 GraphQL + Apollo Client 成为一个非常有吸引力的选项。
我最喜欢 Apollo Client 对 Query 的自动缓存功能。想象一下当载入 https://chii.ai 主页面的时候,它首先会载入所有的动画排名。用户可能会点到别的页面再点回来,由于在第一次 Query 的时候我已经缓存了排名结果,我就不需要再向服务器发送一次请求了。听上去是不是很有吸引力?而 Apollo Client 使得这一切都 work under the hood!
这套缓存系统是如何运作的呢?Apollo Client 对每个发出的 Query 都做了缓存。这听上去挺荒唐,因为以每一个 Query 作为 key 结果直接作为 value 可能占用太多内存了。实际上,GraphQL 里面我们知道返回的数据结构。而不同的Query可能共享同样的数据结构,只不过内容不同。这时候 Apollo Client 将实际返回的数据的 id 和数据结构类型作为 key,返回的数据作为 value。在最理想的情况,每个数据结构里面的子数据结构都有 typename 和 id,这样可以彻底 normalize 所有返回的数据。以 typename 和 id 作为缓存的 key 和直接以 Query 本身作为 key 相比可以大大减少内存占用。
这里面还有一些精妙的东西。比如说你用查询排名的 Query 返回了一连串动画。然后用户点进去其中一个动画,这会发出第二个 Query 请求请求这个动画的 details。第一个 Query 返回动画这个数据结构的列表,第二个 Query 返回一个动画数据结构。由于这个动画具有唯一的 ID,它在缓存里的 key 也是唯一的。那么第二次 Query 的结果实际上会对第一次 Query 里面那个列表里面的动画进行一次更新——它会覆盖先前的值。这么做是自然的,因为两者同属一个数据结构,自然在后端返回的东西应该是一致的。如果你的后端不是这样(比如说某些 API 返回部分 field,另一些 API 又返回另一些 field,甚至同一 field 的内容还不同),那么你会遇到一些 bug。
这个缓存系统听上去挺先进。但是实际上我观察到它也有一些缺点:因为缓存要建 Hash Table,与不缓存的方案相比,它会带来一些时间上的 cost,甚至会造成页面卡顿!这在 fabric 架构下的 React 应用程序简直就是不可忍受的。
有了 Apollo Client 前端的开发其实还不够现代。我们还需要 graphql-codegen 辅助我们自动从 GraphQL Schema 生成可以执行的 Apollo Client Query。那么实际的开发流程就变成了:我需要什么 Query/Mutation,我先写出来,连带上会返回的 schema。我还需要一个 graphql-codegen 配置文件告诉它 server side schema 在哪里。通过一次 yarn generate,我就可以得到直接可以在 Javascript 里 import 的 typed schema,typed query/mutation。这样就可以作为 Typescript 开发的一个良好起点。
毫无疑问,前端全部使用 React Hooks 编写。我使用了微软下一代 UI 库 fluentui northstar。但是其使用还是不如 ant-design 方便,以至于我不得不把 Table 和 Pagination 两个组件按照 antd 的接口通用化了一下下。
整体架构
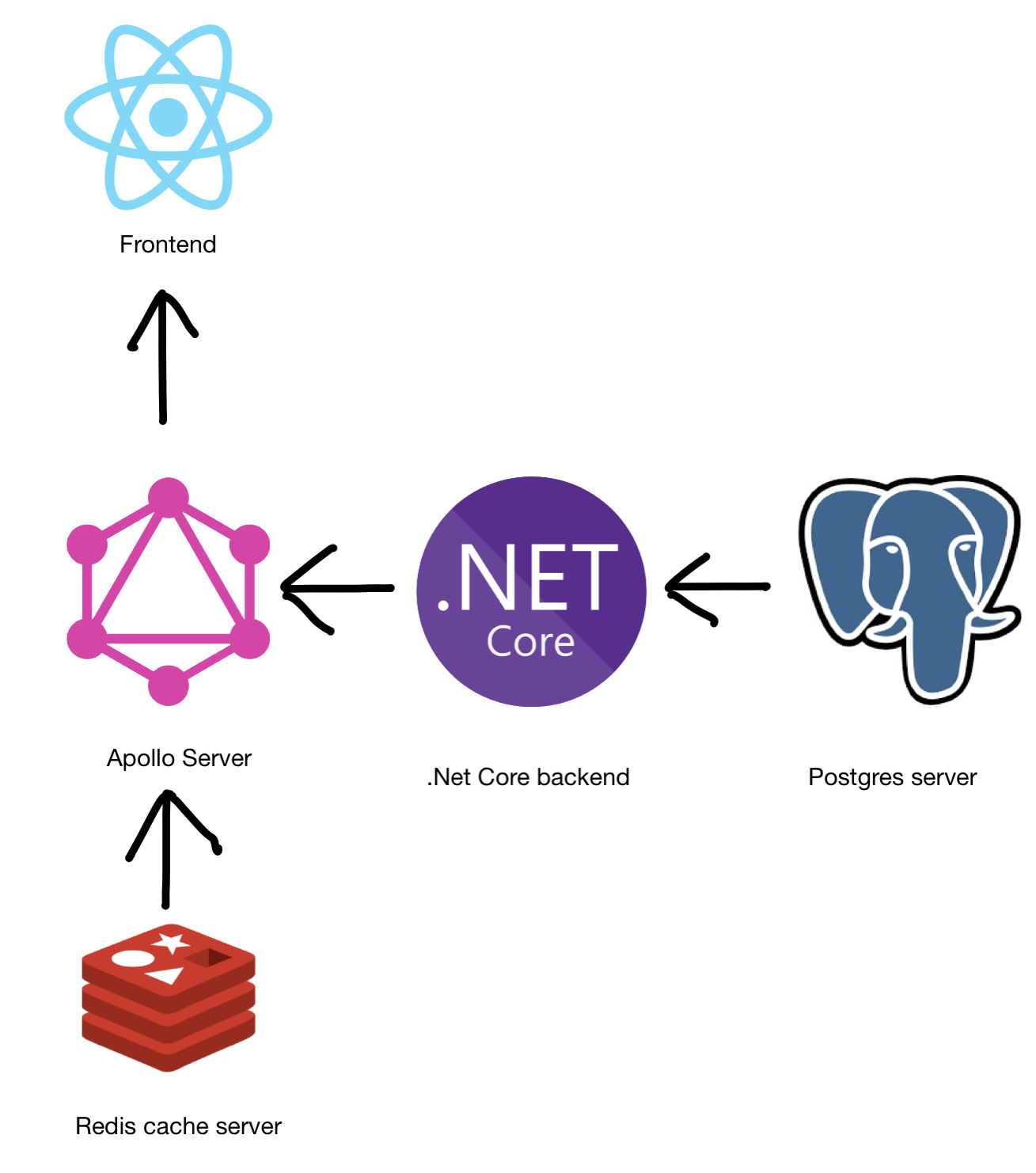
如上图所示,该站整体架构分成五个部分。首先,由 .Net Core 和 Postgers server 构成了后端逻辑的核心。其次,Apollo Server 作为 GraphQL server,运行在 Node 上,其接收前端请求并向真正的后端发出 API 请求。Apollo Server 实际上也封装了某些 Bangumi API,使得其成为一个 API 的 hub。为了减轻后端压力,Apollo Server 后接 Redis 作为 cache。前端是一个 React Application,部署在 Nginx 里面。该网站开发时使用 docker compose,部署在 Azure Kubernetes Service 上。
一些反思
这个架构是否就是最好的架构?恐怕并不是的。我的 GraphQL 服务器并不是原生的 GraphQL 服务,这其实造成了一些 latency:发送一个请求需要通过 GraphQL server 再转接到 .Net Core 的 server。这么做的背后逻辑其实是我想用 GraphQL 那一套生态系统开发,这就产生了后端既有 Restful API 也有 GraphQL 的情形。
如何避免这种用 node server 做 GraphQL server 转接的方式发生?最理想的想法就是后端所有逻辑使用 node 重写。但是我后端主要代码逻辑都在 .Net Core 里面,这样做太浪费时间了。
一种想法是,Apollo Server 所做的主要事情就是一个 resolver。我是否可以在前端使用一个 service worker,把 resolver 作为一个单独的进程,前端主进程只要与这个 service worker 相通信就可以了呢?这样实际上就把一段后端逻辑搬到了前端,而且后端又简化了不少。这需要我深入研究 service worker 的使用方式。