【编者按】此文转载自 https://avnpc.com/。由于原网站链接已经失效,但此文内容非常有价值,故本博客对此文及其相关链接全文转载。本文著作权由 AlloVince 所有。
@[toc]
最近基于 Elastic Stack 搭建了一个日语搜索服务,发现日文的搜索相比英语和中文,有不少特殊之处,因此记录下用 Elasticsearch 搭建日语搜索引擎的一些要点。本文所有的示例,适用于 Elastic 6.X 及 7.X 版本。
日语搜索的特殊性
以 Elastic 的介绍语「Elasticsearchは、予期した結果や、そうでないものも検索できるようにデータを集めて格納するElastic Stackのコア製品です」为例。作为搜索引擎,当然希望用户能通过句子中的所有主要关键词,都能搜索到这条结果。
和英文一样,日语的动词根据时态语境等,有多种变化。如例句中的「集めて」表示现在进行时,属于动词的连用形的て形,其终止形(可以理解为动词的原型)是「集める」。一个日文动词可以有 10 余种活用变形。如果依赖单纯的分词,用户在搜索「集める」时将无法匹配到这个句子。
除动词外,日语的形容词也存在变形,如终止形「安い」可以有连用形「安く」、未然性「安かろ」、仮定形「安けれ」等多种变化。
和中文一样,日文中存在多音词,特别是人名、地名等,如「相楽」在做人名和地名时就有 Sagara、Soraku、Saganaka 等不同的发音。
同时日文中一个词还存在不同的拼写方式,如「空缶」 = 「空き缶」。
而作为搜索引擎,输入补全也是很重要的一个环节。从日语输入法来看,用户搜索时输入的形式也是多种多样,存在以下的可能性:
- 平假名, 如「検索 -> けんさく」
- 片假名全角,如 「検索 -> ケンサク」
- 片假名半角,如「検索 -> ケンサク」
- 汉字,如 「検索」
- 罗马字全角,如「検索 -> kennsaku」
- 罗马字半角,如「検索 -> kennsaku」
等等。这和中文拼音有点类似,在用户搜索结果或者做输入补全时,我们也希望能尽可能适应用户的输入习惯,提升用户体验。
Elasticsearch 文本索引的过程
Elasticsearch (下文简称 ES)作为一个比较成熟的搜索引擎,对上述这些问题,都有了一些解决方法
先复习一下 ES 的文本在进行索引时将经历哪些过程,将一个文本存入一个字段 (Field) 时,可以指定唯一的分析器(Analyzer),Analyzer 的作用就是将源文本通过过滤、变形、分词等方式,转换为 ES 可以搜索的词元(Term),从而建立索引,即:
graph LR Text --> Analyzer Analyzer --> Term
一个 Analyzer 内部,又由 3 部分构成
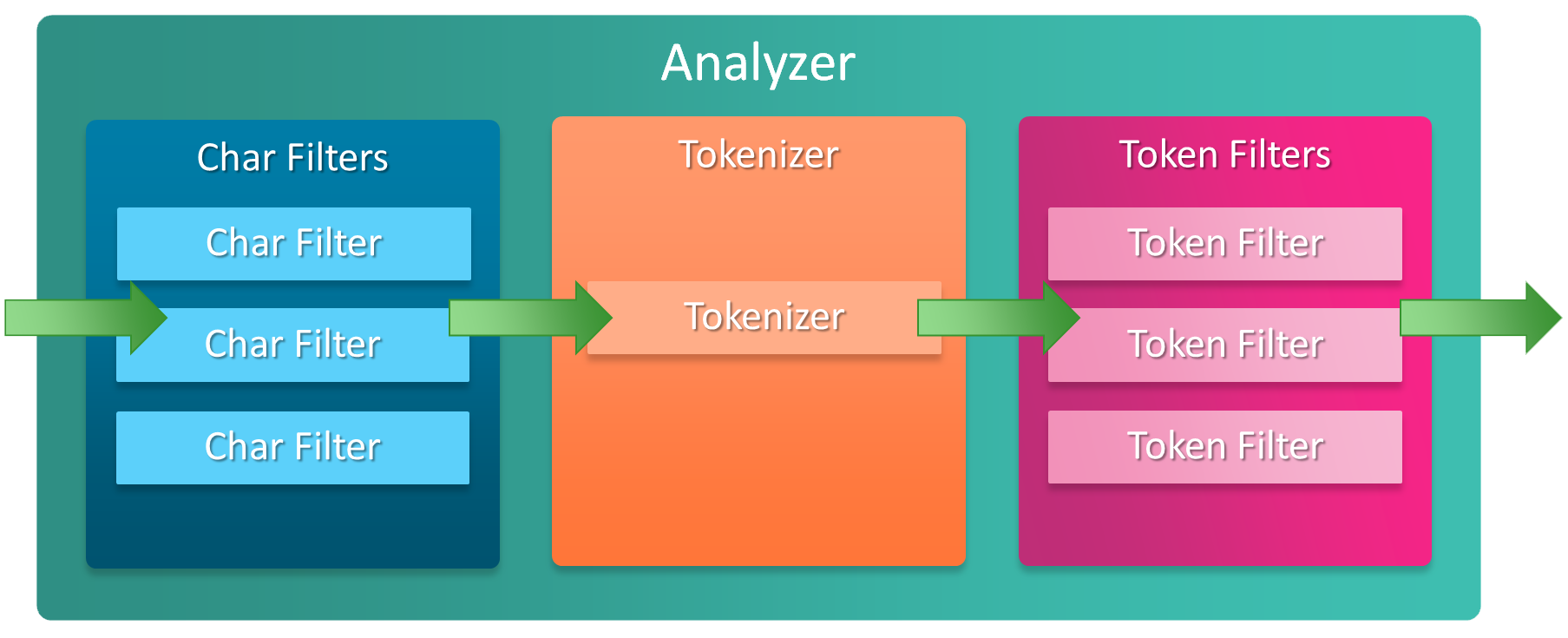
- 字符过滤器 (Character Filter): ,对文本进行字符过滤处理,如处理文本中的 html 标签字符。一个 Analyzer 中可包含 0 个或多个字符过滤器,多个按配置顺序依次进行处理。
- 分词器 (Tokenizer): 对文本进行分词。一个 Analyzer 必需且只可包含一个 Tokenizer。
- 词元过滤器 (Token filter): 对 Tokenizer 分出的词进行过滤处理。如转小写、停用词处理、同义词处理等。一个 Analyzer 可包含 0 个或多个词项过滤器,多个按配置顺序进行过滤。
引用一张图说明应该更加形象
ES 已经内置了一些 Analyzers,但显然对于日文搜索这种较复杂的场景,一般需要根据需求创建自定义的 Analyzer。
另外 ES 还有归一化处理器 (Normalizers)的概念,可以将其理解为一个可以复用的 Analyzers, 比如我们的数据都是来源于英文网页,网页中的 html 字符,特殊字符的替换等等处理都是基本相同的,为了避免将这些通用的处理在每个 Analyzer 中都定义一遍,可以将其单独整理为一个 Normalizer。
快速测试 Analyzer
为了实现好的搜索效果,无疑会通过多种方式调整 Analyzer 的配置,为了更有效率,应该优先掌握快速测试 Analyzer 的方法, 这部分内容详见如何快速测试 Elasticsearch 的 Analyzer, 此处不再赘述。
Elasticsearch 日语分词器 (Tokenizer) 的比较与选择
日语分词是一个比较大的话题,因此单独开了一篇文章介绍和比较主流的开源日语分词项目。引用一下最终的结论
| 算法/模型 | 实现语言 | 词典 | 处理速度 | ES 插件 | Lisence | |
|---|---|---|---|---|---|---|
| MeCab | CRF | C++ | 可选 | 最高 | 有 | GPL/LGPL/BSD |
| Kuromoji | Viterbi | Java | 可选, 默认 ipadic | 中 | 内置 | Apache License v2.0 |
| Juman++ | RNNLM | C++ | 自制 | 高 | 无 | Apache License v2.0 |
| KyTea | SVM 等 | C++ | UniDic | 中 | 有 | Apache License v2.0 |
| Sudachi | Lattice LSTM | Java | UniDic + NEologd | 中 | 有 | Apache License v2.0 |
| nagisa | Bi-LSTM | Python | ipadic | 低 | 无 | MIT |
对于 Elasticsearch,如果是项目初期,由于缺少数据,对于搜索结果优化还没有明确的目标,建议直接使用 Kuromoji 或者 Sudachi,安装方便,功能也比较齐全。项目中后期,考虑到分词质量和效率的优化,可以更换为 MeCab 或 Juman++。 本文将以 Kuromoji 为例。
日语搜索相关的 Token Filter
在 Tokenizer 已经确定的基础上,日语搜索其他的优化都依靠 Token filter 来完成,这其中包括 ES 内置的 Token filter 以及 Kuromoji 附带的 Token filter,以下逐一介绍
Lowercase Token Filter (小写过滤)
将英文转为小写, 几乎任何大部分搜索的通用设置
1 | POST _analyze |
CJK Width Token Filter (CJK 宽度过滤)
将全角 ASCII 字符 转换为半角 ASCII 字符
1 | POST _analyze |
以及将半角片假名转换为全角
1 | POST _analyze |
ja_stop Token Filter (日语停止词过滤)
一般来讲,日语的停止词主要包括部分助词、助动词、连接词及标点符号等,Kuromoji 默认使用的停止词参考lucene 日语停止词源码。 在此基础上也可以自己在配置中添加停止词
1 | POST _analyze |
kuromoji_baseform Token Filter (日语词根过滤)
将动词、形容词转换为该词的词根
1 | POST _analyze |
kuromoji_readingform Token Filter (日语读音过滤)
将单词转换为发音,发音可以是片假名或罗马字 2 种形式
1 | POST _analyze |
1 | POST _analyze |
当遇到多音词时,读音过滤仅会给出一个读音。
kuromoji_part_of_speech Token Filter (日语语气词过滤)
语气词过滤与停止词过滤有一定重合之处,语气词过滤范围更广。停止词过滤的对象是固定的词语列表,停止词过滤则是根据词性过滤的,具体过滤的对象参考源代码。
1 | POST _analyze |
kuromoji_stemmer Token Filter (日语长音过滤)
去除一些单词末尾的长音, 如「コンピューター」 => 「コンピュータ」
1 | POST _analyze |
kuromoji_number Token Filter (日语数字过滤)
将汉字的数字转换为 ASCII 数字
1 | POST _analyze |
日语全文检索 Analyzer 配置
基于上述这些组件,不难得出一个完整的日语全文检索 Analyzer 配置
1 | PUT my_index |
其实这也正是 kuromoji analyzer 所使用的配置,因此上面等价于
1 | PUT my_index |
这样的默认设置已经可以应对一般情况,采用默认设置的主要问题是词典未经打磨,一些新词语或者专业领域的分词不准确,如「東京スカイツリー」期待的分词结果是 「東京/スカイツリー」,实际分词结果是「東京/スカイ/ツリー」。进而导致一些搜索排名不够理想。这个问题可以将词典切换到 UniDic + NEologd,能更多覆盖新词及网络用语,从而得到一些改善。同时也需要根据用户搜索,不断维护自己的词典。而自定义词典,也能解决一词多拼以及多音词的问题。
至于本文开始提到的假名读音匹配问题,很容易想到加入 kuromoji_readingform,这样索引最终存储的 Term 都是假名形式,确实可以解决假名输入的问题,但是这又会引发新的问题:
一方面,kuromoji_readingform 所转换的假名读音并不一定准确,特别是遇到一些不常见的拼写,比如「明るい」-> 「アカルイ」正确,「明るい」的送りがな拼写「明かるい」就会转换为错误的「メイ・カルイ」
另一方面,日文中相同的假名对应不同汉字也是极为常见,如「シアワセ」可以写作「幸せ」、「仕合わせ」等。
因此kuromoji_readingform并不适用于大多数场景,在输入补全,以及已知读音的人名、地名等搜索时,可以酌情加入。
日语自动补全的实现
Elasticsearch 的补全(Suggester)有 4 种:Term Suggester 和 Phrase Suggester 是根据输入查找形似的词或词组,主要用于输入纠错,常见的场景是”你是不是要找 XXX”;Context Suggester 个人理解一般用于对自动补全加上其他字段的限定条件,相当于 query 中的 filter;因此这里着重介绍最常用的 Completion Suggester。
Completion Suggester 需要响应每一个字符的输入,对性能要求非常高,因此 ES 为此使用了新的数据结构:完全装载到内存的 FST(In Memory FST), 类型为 completion。众所周知,ES 的数据类型主要采用的是倒排索引(Inverse Index), 但由于 Term 数据量非常大,又引入了 term dictionary 和 term index,因此一个搜索请求会经过以下的流程。
graph LR TI[Term Index] TD[Term Dictionary] PL[Posting List] Query --> TI TI --> TD TD --> Term Term --> PL PL --> Documents
completion 则省略了 term dictionary 和 term index,也不需要从多个 nodes 合并结果,仅适用内存就能完成计算,因此性能非常高。但由于仅使用了 FST 一种数据结构,只能实现前缀搜索。
了解了这些背景知识,来考虑一下如何构建日语的自动补全。
和全文检索不同,在自动补全中,对读音和罗马字的匹配有非常强的需求,比如用户在输入「銀魂」。按照用户的输入顺序,实际产生的字符应当是
- gin
- ぎん
- 銀
- 銀 t
- 銀 tama
- 銀魂
理想状况应当让上述的所有输入都能匹配到「銀魂」,那么如何实现这样一个自动补全呢。常见的方法是针对汉字、假名、罗马字各准备一个字段,在输入时同时对 3 个字段做自动补全,然后再合并补全的结果。
来看一个实际的例子, 下面建立的索引中,创建了 2 种 Token Filter,kuromoji_readingform可以将文本转换为片假名,romaji_readingform则可以将文本转换为罗马字,将其与kuromoji Analyzer 组合,就得到了对应的自定义 Analyzer ja_reading_analyzer 和 ja_romaji_analyzer 。
对于 title 字段,分别用不同的 Analyzer 进行索引:
title: text 类型,使用kuromojiAnalyzer, 用于普通关键词搜索title.suggestion: completion 类型, 使用kuromojiAnalyzer,用于带汉字的自动补全title.reading: completion 类型, 使用ja_reading_analyzerAnalyzer,用于假名的自动补全title.romaji: completion 类型, 使用ja_romaji_analyzerAnalyzer,用于罗马字的自动补全
1 | PUT my_index |
插入示例数据
1 | POST _bulk |
然后运行自动补全的查询
1 | GET my_index/_search |
可以看到不同输入的命中情况
- gin: 命中
title.romaji - ぎん: 命中
title.reading和title.romaji - 銀: 命中
title.suggestion,title.reading和title.romaji - 銀 t: 命中
title.romaji - 銀たま: 命中
title.reading和title.romaji - 銀魂: 命中
title.suggestion,title.reading和title.romaji








