Bangumi Spider 的历史遗留问题及基于 GitHub Actions 的解决方案
在我的 GitHub 页面里,Bangumi Spider 这个基于 scrapy 的爬虫恐怕是维护时间最久的东西了。从 2015 年为了写 Chi (Bangumi 的好友同步率——推荐系统)开始,这个东西就一直维护到今天。顾名思义,它的主要作用就是爬取所有的用户、所有的条目和用户标记条目的记录。今天,Bangumi Spider 的主要作用是服务于 https://ranking.ikely.me,每月爬取所有标记记录并计算动画排名。动画排名应该每个月第 1 + n 天会更新,n 取决于爬虫爬取速度。
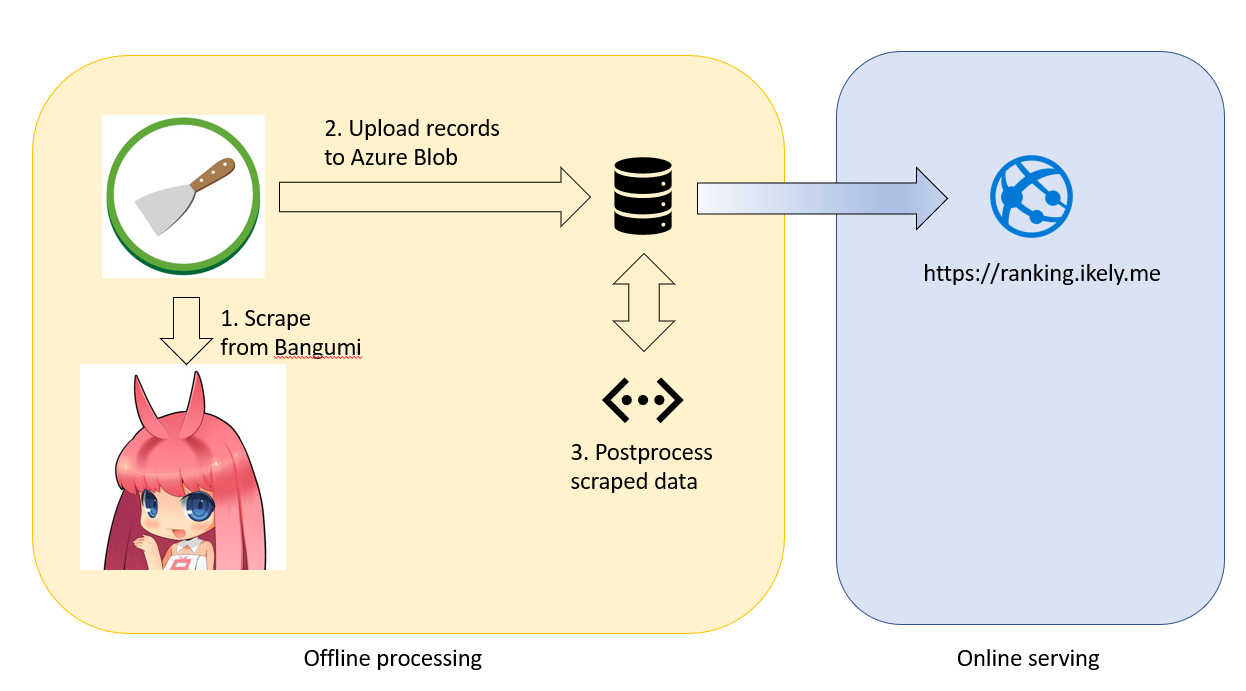
在此图中,左边是理想中的爬虫部分。定时任务首先每月向爬虫服务器 scrapyd 发送爬取请求,爬取后的数据以文本形式放在 Azure Blob 里。然而这时候还是 raw data,需要一个 postprocessing job 对爬取后的数据进行处理形成最后可以直接被 ranking.ikely.me serve 的数据。看上去很简单,是不是?然而在多年的技术发展中,该项目背负了沉重的技术债。
首先,在很久以前,这套东西为了能运行,爬虫服务和应用服务是在同一台虚拟机上的。第一版应用服务用的还是 flask + jinja 一套 SSR。postprocessing job 在 2016 年的时候还是我线下手动生成的,于是在之后的三年里 ranking.ikely.me 一直都没有更新是因为我忘记了线下生成数据的格式。终于在 2018 年,这一套应用用 dotnet core 重写了一遍,并封装成 docker image。scrapyd 被移出虚拟机封装成 docker image。于是该虚拟机就成了 ranking web application docker container instance + reverse proxy。同时为了能自动化生成排名数据,postprocessing job 被移到了该虚拟机里面。postprocessing job 运行时所需要的内存巨大,在去年大约要 10 GB 内存(在今年涨到了 14 GB)。crontab job 也被写在了该虚拟机里面。这一套系统运行了六个月,然后又不能自动更新排名了,因为 Bangumi 页面样式更新使得某些数据无法爬取。这里面存在的问题有:
- Azure 虚拟机高配置而长时间空转,浪费 budget;
- scrapyd container instance 在爬取数据过后还会重启,丢失已部署的爬虫,经调查有不法人士黑入该 instance;
- ranking web application 并非 continuously deployed,需要手动更新;
在理想的状况下,每一个部件应该自动化运行并充分利用现有 budget。而 GitHub Actions 的出现,为实现这种理想提供了便利(当然,需要指出的是,GitHub Actions 并未唯一实现这种自动化的手段)。在图的每一个被标记的部分都应该有自动化:
- crontab job 自动化
- 自动按需启动 scrapyd server 并在运行结束关闭
- 自动按需启动 postprocessing job 并在运行结束关闭
- 随着爬虫的更新,postprocessing job 也应该更新
即使不能做到 100% 自动化,能大幅降低服务空置率也是对宝贵 budget 的一种有效利用。此外,我希望将 ranking web application 移出虚拟机,用 Azure web service (Linux) + container 的技术去 serve,以降低成本。
GitHub Actions
GitHub Actions ,据官方描述,能够极大简化你的 CI/CD 流程。但实际上它能做的事情不仅局限于 CI/CD。在这篇文章中,我将介绍 Bangumi Spider 新添加的 GitHub Actions 如何实现自动化部署和排名自动化更新。
在 Bangumi Spider 里面,有一个叫做 scrapyd 的 folder 存放了 Bangumi Spider 专属 scrapyd dockerfile,其和普通的 scrapyd 不同之处在于使用 nginx 在访问前进行一次验证。在这个 workflow 里面,GitHub Actions 先 build docker image,再 publish 到 Docker Hub,最后更新 Azure container image。
正如上文所述,我不希望 scrapyd 在不执行爬虫任务的时候运行,所以我在最后关闭了它。在另一个定时 workflow 里面,我启动相应的 Azure container service,在线部署爬虫并运行爬取用户记录番组的数据和番组数据的 jobs。
另一个叫 postprocess 的 folder 存放了对已爬取进行后处理的 Dockerfile。其执行任务净是一堆脚本文件,以单机有限资源处理百万行数据。这是一个有艺术性的话题,但是我不想讲。针对这个 Docker image 的构建 workflow 被描述在这个文件里。相应地,我在另一个 workflow 定时启动相应的 Azure container service,运行完成就结束。
需要指出的是,在这里我发现了 GitHub Actions 是可以支持每次 commit 所触动的文件而出发 Actions 的——倒不如说我发现 Travis CI 不支持这项功能。这样我每次提交的时候我就可以通过检查修改的文件是否涉及 scrapyd 和 postprocess 两个 folder 而 conditionally update docker images。就这项功能而言,我觉得 Travis CI 已经完全落伍了。
Azure Web App Service
Azure 提供 App Service 的服务,并附带一个 Azure 的证书,而且也可以绑定到自己的域名。关键是这个服务的价格比自己 host 虚拟机要便宜(如果用 Basic plan 的话)。App Service 最好的地方在于支持 docker image 和 docker-composed images,于是我把 dotnet core 的服务也使用 docker image 部署在其上。https://ranking.ikely.me 使用 CloudFlare 做 CDN 并由其提供证书,关于如何把 CloudFlare 的证书导入到 Azure App Service 的操作参见这篇文章。
Achievements
通过这么一番操作,我们已经:
- 100% 实现了全自动无人干预更新排名(除非 Sai 老板再次更新 Bangumi 页面导致爬虫需要连带更改)
- Conditionally update docker image
- 大幅削减预算:从每月七十多刀的虚拟机削减到十四刀左右。
- 增强了 scrapyd 的安全性。